Continuing Modeling the Debate Flow
If you haven’t read the previous post, here’s the TLDR: a policy debate round can be modeled as a directed graph where argument claims are nodes, logical dependencies are edges, and the strength of any claim propagates mathematically from the nodes upstream of it. Attacking uniqueness zeroes the node, which cascades forward and collapses the entire DA. A turn flips the polarity of an impact, converting the NEG offense into the AFF offense. Fragility analysis tells you which node, if removed, does the most damage.
Since publishing the original Modeling the Debate Flow post, I’ve received a lot of questions about how the model works (and a lot of wows). Motivated by that, I’ve decided to continue working on the model and write a follow-up post that goes deeper into the implementation details, runs more experiments, and explores some of the strategic implications for debaters.
The Problem with a Static Graph
The first implementation had a pro and an obvious flaw. The pro: you could take any set of arguments, assign probabilities, run the propagation function, and get a precise expected value for each side. The flaw: debate isn’t static. The same DA that’s terrifying in the 1NC is worthless if the 2AR gets two minutes to explain why the uniqueness is gone. Arguments over a debate evolve across eight speeches, gaining strength through extension and losing it through answers, sometimes disappearing entirely when nobody addresses them.
A frozen graph could tell you the potential value of an argument, however it can’t tell you the realized value after two AFF debaters spend 9 minutes tearing it apart.
To fix this, I’ve went back to the workshop and made a better model that models the round as a dynamic process, not a snapshot — to simulate what actually happens speech by speech and let the final state of the flow determine the scoring.
Simulating Eight Speeches
The flow engine assigns each debater a cover capacity — which is a number derived from their speed rating and technical level that represents how many argument units fit in a given speech. A fast, organized debater might cover 6-7 units in an 9-minute speech, however a slower debater might cover 4. This difference matters because arguments that don’t get covered get dropped, and dropped arguments have a different fate than answered ones during a round.
In a debate round, each speech has a specific job in the structure:
The 1NC has a brutal tension built into it: it needs to introduce every NEG off-case position and respond to the AFF case. It almost never has time to do both completely. Arguments the 1NC concedes on the AFF case — because the debater ran out of capacity — are marked as strengthened for the AFF. Those concessions become one of the most reliable AFF paths to winning the round.
The 1AR is the speech where rounds get decided in ways that often aren’t apparent until the 2NR. It’s only 6 minutes responding to a full 15-minute neg block, and debaters routinely drop one or two extended NEG positions. The engine tracks this carefully: anything dropped in the 1AR becomes the highest-priority target for the 2NR, thus the reason why the 1AR is often considered to be the most important and hardest speech to give in a round.
The 2NR selection logic reflects something real about how good 2NRs actually work. The algorithm checks for dropped AFF arguments first, before it looks at the best-extended NEG positions:
python code snippet start
# Priority 1: extend dropped AFF args — they're conceded, no work required
for aff_drop in dropped_aff[:2]:
if covered < cap:
aff_drop.current_prob = min(0.97, aff_drop.current_prob + EXTENSION_BOOST * 2.0)
chosen_strategy.append(f"AFF dropped: {aff_drop.name}")
# Priority 2: best extended NEG off-case position
for arg in neg_options[:2]:
if covered >= cap:
break
arg.current_prob = min(0.97, arg.current_prob + EXTENSION_BOOST * 2.0)
chosen_strategy.append(arg.name)python code snippet end
The first question a good 2NR asks is always “what did they drop?” The model asks the same question in the same order.
A Real Round Simulation!
I ran this round through the engine directly. The AFF runs a plan restoring collective bargaining rights for federal workers (which is actually the plan I run!). The NEG responds with Politics DA, Productivity DA, and Gov Efficiency DA in front of a policy judge.
Here’s the speech-by-speech flow:

Note: Some speeches might be out of order, because it’s ordered alphabetically.
Each row is an argument. Columns are the eight speeches. “read” means first introduced that speech, “↑ ext” means extended, “~ ans” means the other side answered it, “drop/DROPPED” means nobody addressed it.
The two things that decide this round happen in the first two speeches.
In the 1NC, the NEG runs six off-case positions — three DAs — and only has capacity to answer one AFF case argument. Both Worker Exploitation / Wage Stagnation and Democratic Participation / Civic Power go untouched. They’re now marked strengthened for the AFF with no NEG response on the flow.
In the 2AC, the AFF answers everything the NEG brought — but in doing so, runs out of time. Political Capital Exists Now and Essential Service Failure get dropped. Both immediately become the 2NR’s priority targets.
At the end of the round, here’s what the engine’s has decided for its ballot:
code snippet start
Winner : AFF
Confidence: 40% Margin: +53.6
AFF score : +93.57 NEG score: +39.96
AFF DROPPED — NEG extends freely (2):
Political Capital Exists Now
Essential Service Failure → Public Safety Crisis
2NR: 2 position(s) extended
Lynchpin: Political Capital Exists Nowcode snippet end
The AFF wins despite dropping two arguments — and wins more comfortably than you might expect given those drops. The reason is systemic: the two AFF case impacts the NEG never answered are both high-magnitude. Worker exploitation and democratic participation, running uncontested through every speech, collectively score more than the two dropped NEG arguments the 2NR extended. Hence, even with the drops, the AFF still wins by a wide margin. The model captures this nuance — that not all drops are created equal, and that sometimes conceding a low-magnitude argument is worth it if it means keeping the high-magnitude ones alive.
The lynchpin call is worth noting. Political Capital Exists Now is flagged as the highest-fragility node in the NEG position — the uniqueness for the Politics DA. If the AFF had contested it in the 2AC instead of dropping it, the entire DA chain collapses. The AFF was one argument away from a much cleaner win; the decision to cover everything else instead turned out to be the structural bottleneck.
Dropped Arguments and Why They’re Treated Differently
The scoring rule for drops formalizes something every debater already knows: a dropped argument is a true argument.
When an argument is answered, its probability is multiplied by 0.55 — the judge has heard both sides and discounts the original claim. When an argument is dropped, its probability jumps to 0.92 — close to certainty. Not 1.0, because even conceded arguments aren’t always extended cleanly and a 2NR that forgets to extend its own drop doesn’t get full credit. But nearly.
The asymmetry compounds fast. An argument answered in the 2AC at probability 0.65, answered again in the 1AR, might sit at 0.28 by the 2NR — less than a third of its original strength. The same argument dropped in the 2AC sits at 0.92 with two speeches of free extension time. That’s roughly a 3x gap, which for a high-magnitude argument is the difference between a close round and a blowout.
This is the mathematical reason experienced 1NCs read more arguments than the 2AC can comfortably answer. It’s not about winning all of them — it’s about creating structural pressure that forces the 2AC to prioritize, knowing something will fall through.
Judge Paradigm as a Bias Layer
The model runs two judge types that reflect the real split in college policy: a policy judge and a K judge.
python code snippet start
"policy": {
ArgCategory.DA: 1.05, # DAs score slightly above face value
ArgCategory.KRITIK: 0.78, # Ks discounted unless the link is specific
tech_over_truth: 0.88 # drops matter, but not absolutely
},
"k_judge": {
ArgCategory.DA: 0.90, # DAs discounted slightly
ArgCategory.KRITIK: 1.12, # Ks score above face value
tech_over_truth: 0.78 # more willing to look past a technical drop
}python code snippet end
A policy judge weights DA impacts 5% above their raw activation score and discounts Ks by 22%. The same Cap K that’s a strong 2NR choice in front of a K judge activates at 78% of its nominal value in front of a policy judge — often not enough to outweigh two well-extended DAs. Swapping the Gov Efficiency DA for Cap K in the labor round and running it against a K judge shifts the lynchpin entirely: the framework question becomes the highest-fragility node instead of uniqueness, and the NEG’s optimal strategy changes with it.
tech_over_truth controls how strictly the judge treats drops. A policy judge at 0.88 gives significant weight to dropped arguments but doesn’t treat them as automatic wins — there’s still some discount for arguments that seem implausible even without a response. A K judge at 0.78 exercises more independent judgment. In practice this means the labor round’s AFF margin actually narrows slightly against a K judge, because that judge’s discounting of conceded arguments cuts both ways.
The Full Round Graph
Both argument structures evaluated simultaneously:
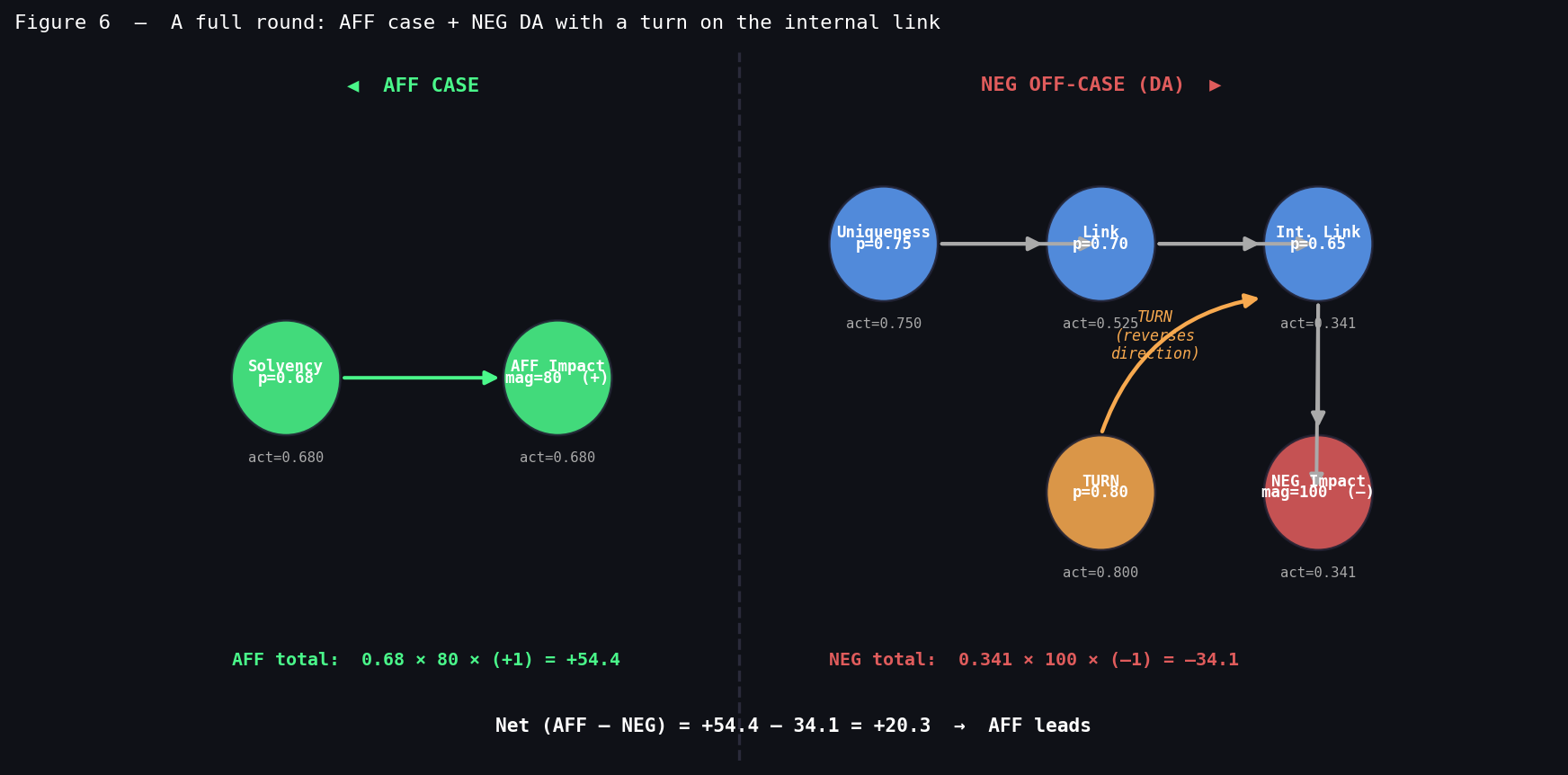
The round score is the difference between the AFF impact activations and the NEG impact activations, with diminishing returns on each side’s second and third strongest arguments — replicating the fact that a judge can only track so much impact calculus across the final speeches.
The turn in the graph — the orange arrow into the NEG internal link — is the most structurally interesting feature. When it activates, the NEG’s own impact flips to AFF offense. The swing isn’t just “we removed –34 points,” it’s “we converted –34 into +34” — a 68-point total swing from winning a single argument. This is the mathematical reason a good impact turn is worth more than most defensive blocks.
What the Model Gets Wrong
It’s worth it to be direct about what the model fails to cover. Took me hours to work through this, but the model will always have limits. Some of these are technical limitations that could be improved with more time, but others are fundamental to the nature of debate and can’t be fully captured by any mathematical model.
Two judge types is a simplification. Real judge diversity is much wider — a policy judge who regularly judges K rounds sits somewhere between the two presets, and the model can’t capture that. The archetypes are useful for showing how paradigm biases shift the structural analysis, not for predicting any specific judge’s ballot.
Framework debates aren’t fully modeled. When a K wins the framework, the judge may ignore the DA stack entirely rather than just discounting it. That’s not a probability shift on individual nodes — it’s a change to which nodes count at all. The model approximates this through category bias, but a full framework win is more categorical than any multiplier captures.
Rhetorical performance is invisible. A judge moved by a clear, confident 2NR might vote NEG even when the model’s expected value favors the AFF. The engine captures structural disadvantage, not whether someone explained their argument well under pressure.
The ballot prediction is rougher than the structural diagnosis. The most reliable output isn’t “who wins” but rather more about “given this argument structure, which node has the highest fragility, and what’s the cost of dropping it.”
In the labor round, the answer is plain: the AFF drops Politics DA uniqueness in the 2AC, the entire DA chain is one concession away from collapsing, and the margin lands at +53 instead of something much wider. That’s a recoverable round. But the model shows exactly where it got expensive.
What’s Next?
Something that I look forward to is expanding this to more arguments and more complex structures. Another is building a website where you can interactively work with the engine and see it in action. Currently, the only way to use it is through the command line, which is fine for me but for most people, a visual interface would be much more intuitive.
Open Source
Code and argument library will be available on my GitHub. The engine runs two judge archetypes — policy and K — tracks all eight speeches, and persists season analytics across sessions. Run with --interactive for the full CLI.